What is Text Recognition (OCR)
Optical Character Recognition (OCR) is a technology that reads documents and transforms any visible text into a format that the computer can read. This helps users extract text from images or scanned documents.
Introduction
DataSnipper uses intelligent Optical Character Recognition (OCR) to run text recognition on documents. This enables you to search and extract text from PDFs, scans, and images. After importing a document in DataSnipper, all texts, images, and PDFs will be analyzed automatically. However, in some cases, the automatic text recognition might not work due to the complexity of the document like analyzing manual writing.
Choose your DataSnipper version to learn more about Text Recognition:
👉 DataSnipper version 4.0 and earlier
👉 DataSnipper version 5.0 and later
or
👉 Visit FAQs on Text Recognition (OCR)
DataSnipper v4.0 - Text Recognition
Use Text Recognition
Run Text Recognition Manually
Let's start
- To re-run the text recognition, click the "recognize text" button.
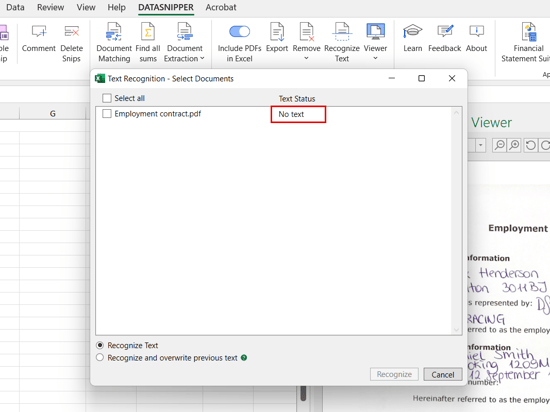
- DataSnipper will indicate that no text was found in the first go.
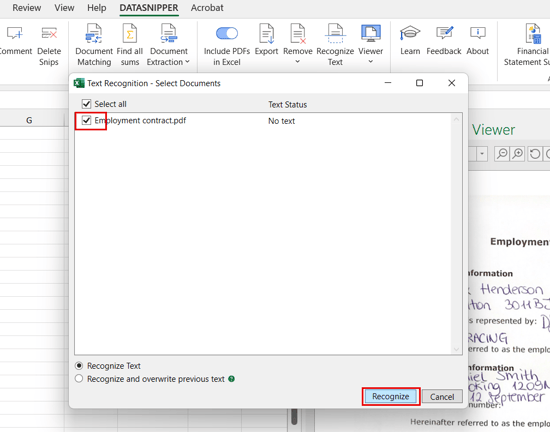
- Run the test to recognize the text in the document again.
DataSnipper v4.0 - Facts about Text Recognition
- Text Recognition will enhance the quality of the PDF text by default when pages do not contain text
- Handwritten Text Recognition supports: English, Chinese Simplified, French, German, Italian, Portuguese, and Spanish
- Text Recognition supports all languages in Latin, Cyrillic, Chinese, Japanese, and Korean scripts
- Quality and language support of text recognition is always improving, you can find the most up-to-date status per language on the computer vision language support page.
DataSnipper v4.1 and later - Text Recognition
Use Text Recognition
Run Text Recognition Manually
Let's start
- To run the text recognition, click the "OCR" button in the DataSnipper Ribbon.
- DataSnipper will indicate the Text Status as either "No text" or "Contains text" depending on what it was able to recognize without applying OCR to the documents.
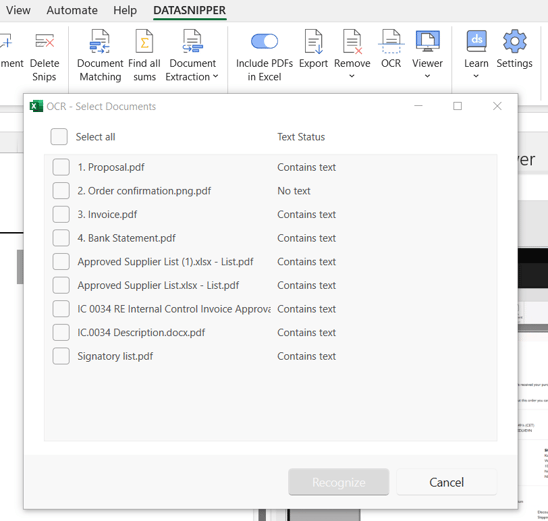
- Click on Select All and then select "Recognize" to run Text Recognition on all imported files.
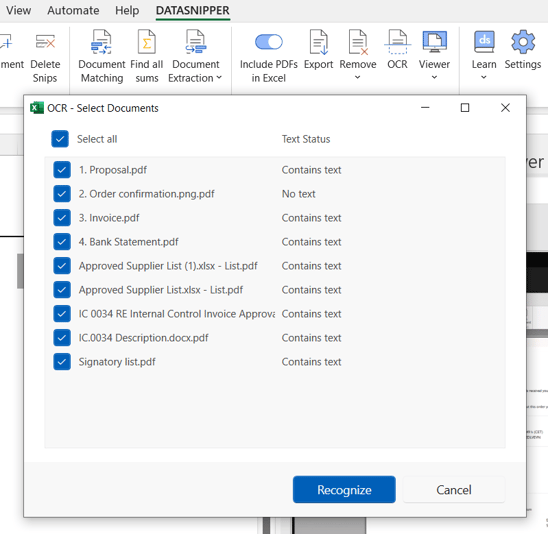
- DataSnipper will preemptively prompt an automatic request to OCR if you have imported pictures or scans. If you've clicked on that before doing the manual Text Recognition, then it will not be possible to run the OCR again on those documents.
Facts about Text Recognition
- Text Recognition will enhance the quality of the PDF text by default
- Text Recognition supports all languages in Latin, Cyrillic, Chinese, Japanese, and Korean scripts
- Handwritten Text Recognition supports English, Chinese Simplified, French, German, Italian, Portuguese, and Spanish
DataSnipper v5.0 - Text Recognition
Run Text Recognition Manually
Let's start
- To run the text recognition, click the "OCR" button in the DataSnipper Ribbon.
- DataSnipper will indicate the Text Status as either "No text" or "Contains text" depending on what it was able to recognize without applying OCR to the documents.
- Click on Select All and then select "Recognize" to run Text Recognition on all imported files.
- DataSnipper will preemptively prompt an automatic request to OCR if you have imported pictures or scans. If you've clicked on that before doing the manual Text Recognition, then it will not be possible to run the OCR again on those documents.
Facts about Text Recognition
- Text Recognition will enhance the quality of the PDF text by default
- Text Recognition supports all languages in Latin, Cyrillic, Chinese, Japanese, Hindi, Indian, and Korean scripts and dialects
- Handwritten Text Recognition supports English, Chinese, Japanese, Korean French, German, Italian, Portuguese, and Spanish
- If you'd like to see a complete list of languages supported in DataSnipper v5.0, please visit this link.
How DataSnipper OCR Handles Data Residency
When using DataSnipper's built-in OCR, the text recognition processing is handled by a dedicated OCR resource that is dynamically deployed based on your organization's license location (Azure service regional availability). This means your document data is processed within the region associated with your license, helping to meet data residency and compliance requirements.
FAQs
- Does DataSnipper recognize handwritten text?
DataSnipper can recognize text in handwritten form as long as it is legible. You can find the most up-to-date status per language on the computer vision language support page. - When is OCR applied by DataSnipper?
OCR is applied on the following user actions:
i. Upon importing documents that do not have a text layer (e.g., images and scanned documents), DataSnipper will prompt a notification in which it asks whether you would like Text Recognition to be applied.
ii. Upon selecting the Text Recognition button in the DataSnipper tab and applying it to the selected documents. - How can I run Text Recognition on a document that already contains text?
You can use the 'Recognize Text' button and then choose the option 'Recognize'.
Please note that for versions before v4.1 you need to select the ‘Recognize and overwrite option’. - Where is my document data processed when using OCR? When using DataSnipper's built-in OCR, your documents are processed by a dedicated OCR resource deployed in the region associated with your organization's license. This is done to support data residency requirements. Each organization's OCR processing is isolated. If you need to confirm your processing region, contact DataSnipper Support.