O que é Text Recognition?
O reconhecimento óptico de caracteres - Optical Character Recognition (OCR) - é uma tecnologia que lê documentos e transforma qualquer texto em um formato legível para computadores. O nosso recurso Text Recognition utiliza a tecnologia avançada OCR permitindo a extração de texto de imagens e até mesmo de documentos digitalizados.
Introdução
O DataSnipper usa OCR para extrair texto de PDFs, digitalizações e imagens, facilitando a busca e extração de informações. Em casos mais complexos, como textos escritos à mão, o desempenho pode variar.
Escolha a sua versão do DataSnipper para aprender mais sobre Text Recognition
👉 Versão 4.0 e anteriores do DataSnipper
👉 Versão 5.0 do DataSnipper e mais recentes
ou
👉 Consulte as nossas perguntas frequentes sobre o recurso Text Recognition (OCR)
DataSnipper versão 4.0 - Reconhecimento de texto
Tutorial
Executar o Text Recognition manualmente
Como começar?
- Execute novamente o recurso clicando no botão "Recognize text" (Reconhecer texto).

- Na primeira vez, o DataSnipper indicará que nenhum texto foi encontrado.

- Execute o teste novamente para que o texto seja reconhecido.

DataSnipper versão 4.0 - Fatos sobre o reconhecimento de texto
- O recurso de reconhecimento de texto melhora a qualidade do texto em PDFs, por padrão, quando as páginas não contêm texto.
- O recurso de reconhecimento de texto suporta texto escrito à mão em línguas como o inglês, chinês simplificado, francês, alemão, italiano, português e espanhol.
- O reconhecimento de texto suporta todos os idiomas em scripts latinos, cirílicos, chineses, japoneses e coreanos.
- A linguagem e a qualidade do recurso de reconhecimento de texto estão sempre melhorando. Você pode encontrar as informações mais recentes na página oficial de suporte de idiomas.
Versão 4.1 do DataSnipper e mais recente
Tutorial
Executar Text Recognition manualmente
Vamos começar?
- Para executar o reconhecimento de texto, clique no botão “OCR” na faixa de opções de DataSnipper.

- O DataSnipper indicará o estado do texto como: “No text” (Sem texto) ou “Contains text” (Contém texto) dependendo dos resultados encontrados nos seus documentos.
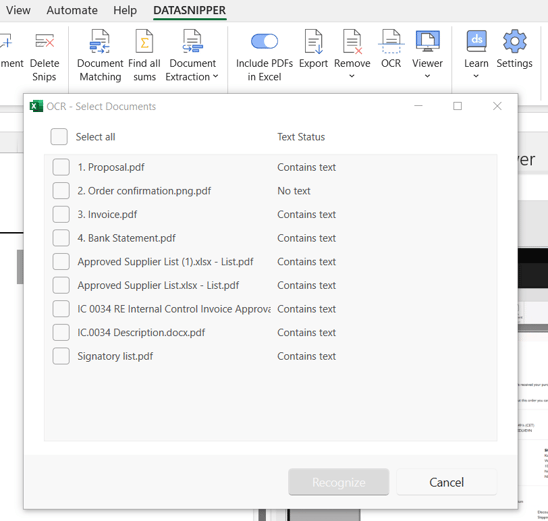
- Clique em “Select all” (Selecionar todos) e depois selecione “Recognize” (Reconhecer) para executar o recurso Text Recognition em todos os arquivos importados.
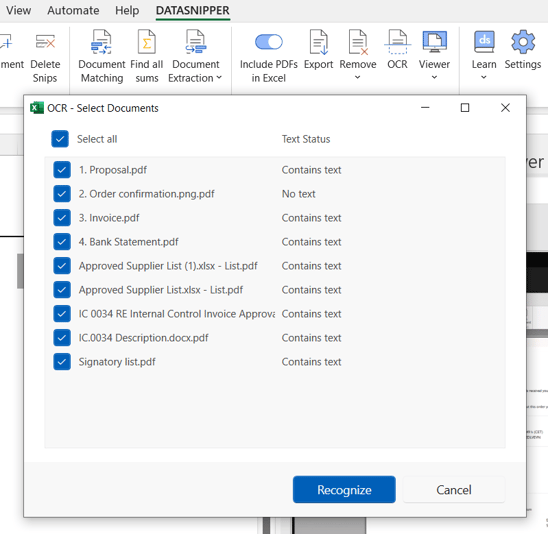
- O DataSnipper enviará previamente uma mensagem automática requisitando que o OCR reconheça texto nas imagens ou digitalizações que você importou. Porém, se você já usou o recurso antes, então não será possível executar, nesses documentos, o OCR outra vez.
Fatos sobre o recurso Text Recognition versão 4.1
- OCR melhora a qualidade do texto de um PDF.
- O reconhecimento de texto suporta todos os idiomas em scripts latinos, cirílicos, chineses, japoneses e coreanos.
- O reconhecimento de texto suporta todos os idiomas em scripts latinos, cirílicos, chineses, japoneses e coreanos.
- O recurso de reconhecimento de texto suporta texto escrito à mão como: inglês, chinês simplificado, francês, alemão, italiano, português e espanhol.
DataSnipper versão 5.0 - Reconhecimento de texto
Executar Text Recognition manualmente
Vamos começar?
- Para executar o reconhecimento de texto clique no botão “OCR” na faixa de opções de DataSnipper.
- O DataSnipper indicará o estado do texto como: “No text” (Sem texto) ou “Contains text” (Contém texto) dependendo dos resultados encontrados nos seus documentos.
- Clique em “Select all” (Selecionar todos) e depois selecione “Recognize” (Reconhecer) para executar o recurso “Text Recognition” (Reconhecimento de Texto) em todos os arquivos importados.
- O DataSnipper enviará previamente uma mensagem automática requisitando que o OCR reconheça texto nas imagens ou digitalizações que você importou. Porém, se você já usou o recurso antes, então não será possível executar, nesses documentos, o OCR outra vez.
Fatos sobre o recurso Text Recognition versão 5.0
- OCR melhora a qualidade do texto de um PDF.
- O reconhecimento de texto suporta todos os idiomas e dialetos em scripts latinos, cirílicos, chineses, japoneses e coreanos.
- O recurso de reconhecimento de texto suporta texto escrito à mão como: inglês, chinês simplificado, francês, alemão, italiano, português e espanhol.
- Se você deseja ver a lista completa de idiomas que são suportados pelo DataSnipper v5.0, visite este link.
FAQs - Perguntas frequentes
1. O DataSnipper reconhece o texto escrito à mão?Sim. O DataSnipper consegue reconhecer texto escrito à mão, como por exemplo, assinaturas e rubricas, desde que as mesmas sejam legíveis. Você pode encontrar as atualizações mais recentes na página de suporte a idiomas.
2. Quando é que o OCR é aplicado pelo DataSnipper?
O OCR - reconhecimento óptico de caracteres é aplicado nas seguintes situações:
- Ao importar os documentos que não têm uma layer de texto como por exemplo, uma imagem e/ou um documento digitalizado. Nesse caso, o DataSnipper perguntará se você deseja aplicar “Text Recognition” (Reconhecimento de Texto) a esses documentos.
- Ao selecionar o botão “OCR” na faixa de opções do DataSnipper para aplicar esta funcionalidade a todos os documentos selecionados.
3.Como é que eu executo o recurso Text Recognition em um documento que já contém texto?
Clique no botão “OCR” e depois escolha a opção 'Recognize' (Reconhecer). Observe que para as versões anteriores à v.4.1, você precisa selecionar ‘Recognize and overwrite option’ (Reconhecer e substituir opção).