Not all PDFs are produced in the same way, and different information can be encoded in a PDF depending on how it is produced. This can involve hidden data, metadata, as well as security implementations. Occasionally when working in DataSnipper, you may encounter some PDFs that result in error messages when trying to process.
Resolving the error message
If you do encounter an error message when working with a particular PDF, there are a couple of things that can be done to try and resolve the issue:
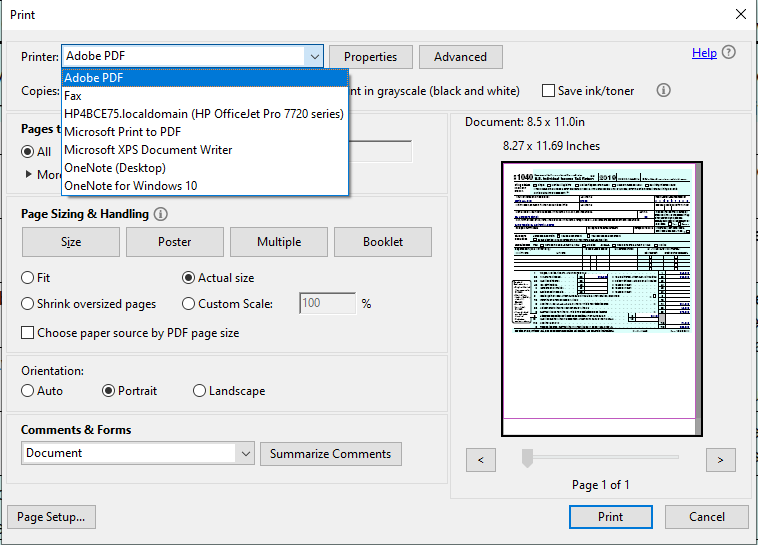
- Print the PDF to a new PDF file using Adobe Acrobat. This can be done by selecting File > Print in Acrobat and then selecting either 'Adobe PDF' or 'Microsoft Print to PDF' from the drop-down menu:
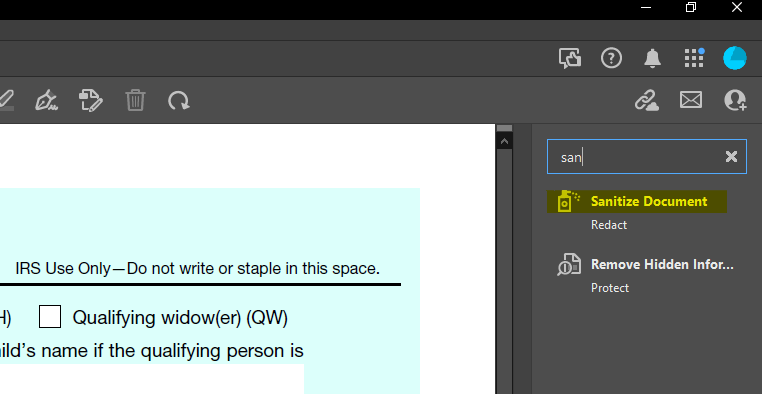
- Adobe Acrobat also offers the ability to 'Sanitize' PDF documents. This removes any hidden data and meta-data contained in the file and can improve machine readability:
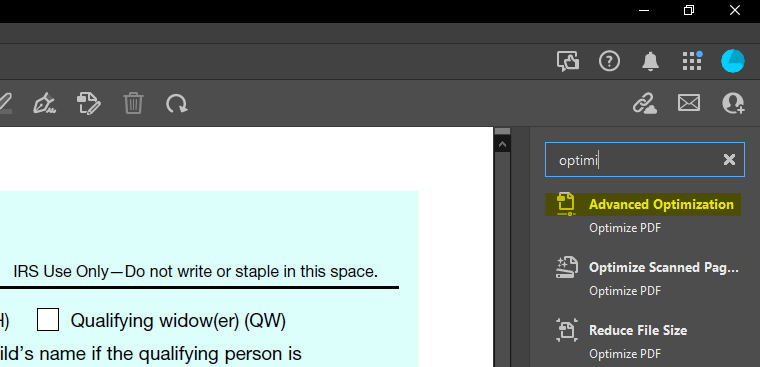
- Finally, you can use the 'Advanced Optimization' tool in Adobe Acrobat. This provides comprehensive functionality in terms of removing unwanted or unnecessary information that may be preventing the PDF from being processed correctly in DataSnipper:
From the Advanced Optimization window, you can modify the document to remove many features that are not relevant. A few of the tabs to consider are the 'Discard Objects', 'Discard User Data', and 'Clean Up':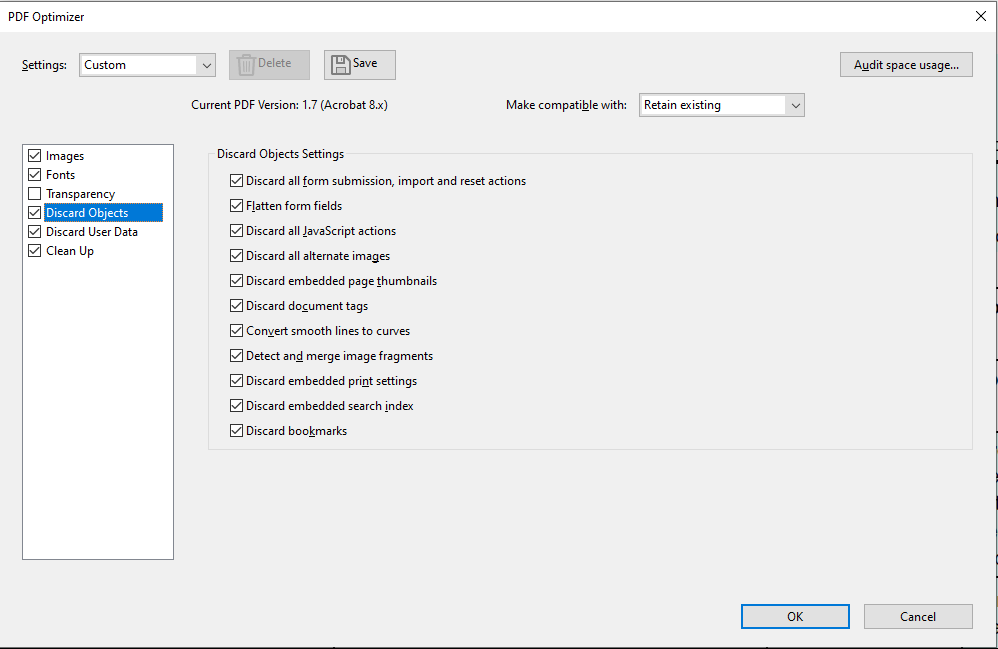
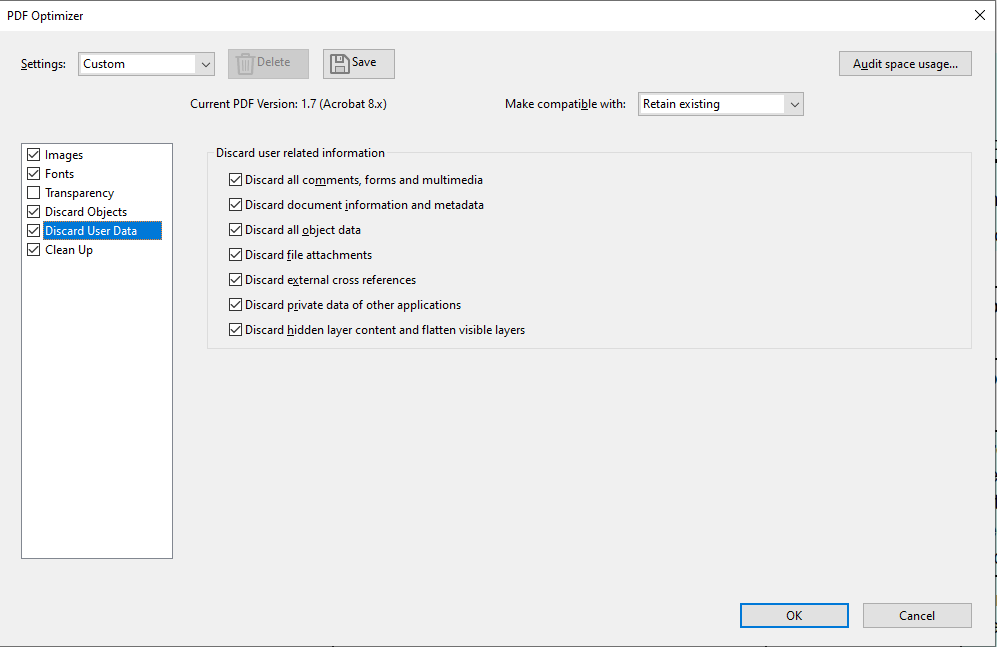
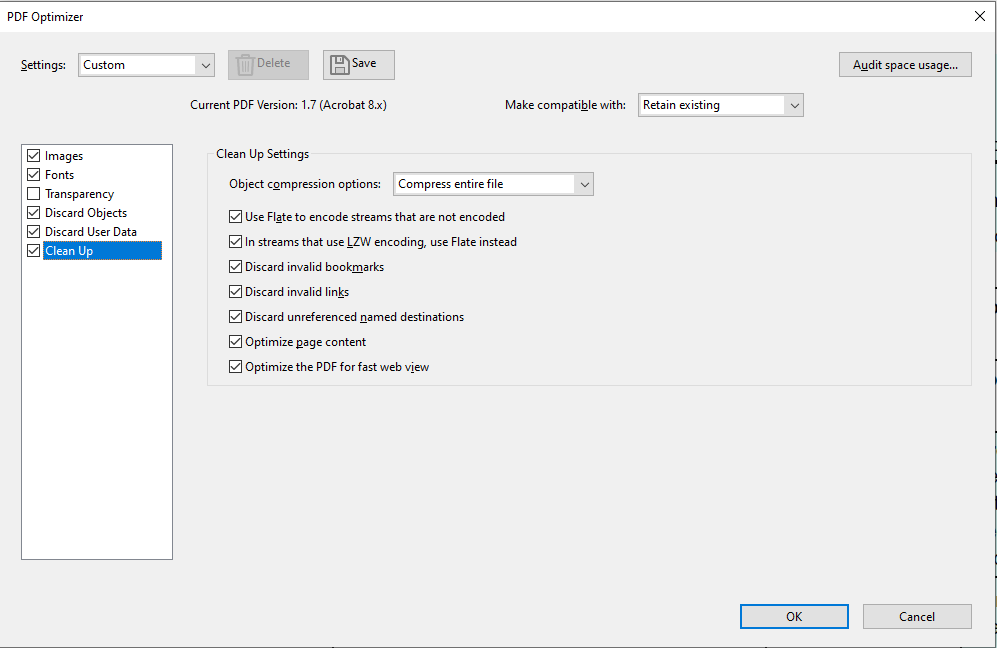
- After running through these processes, it is recommended to print the file to a new PDF (this will ensure the information is encoded in a new PDF file). It also ensures that the original copy of the document can be retained.
Following these steps should ensure that you can work with your PDF in DataSnipper. If you continue to experience any issues with particular PDF documents, please reach out to support@datasnipper.com for further assistance.