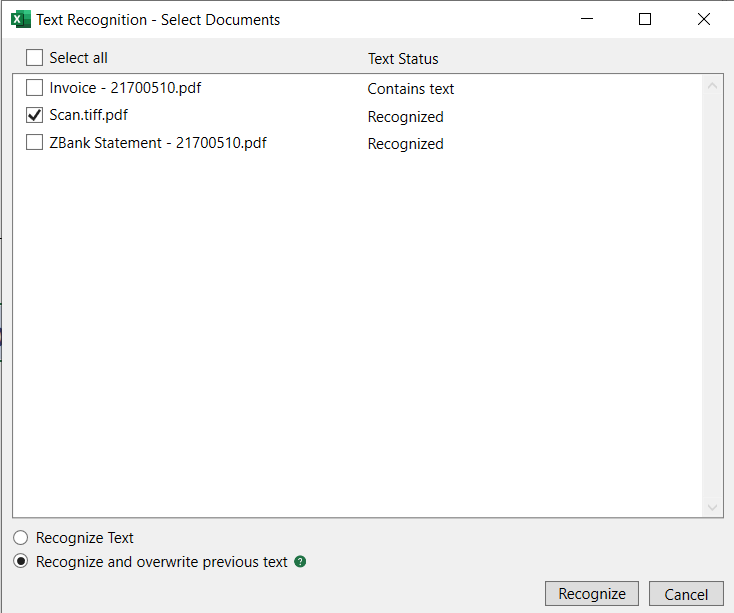
DataSnipper duplicate or unexpected text - issue summary
There are times when the OCR functionality from other programs, or scanning documents, adds a text layer over the existing text within the document. In these cases when you make a snip you may see the same text showing up twice in the cell contents.
You can see examples of duplicate or unexpected text below:
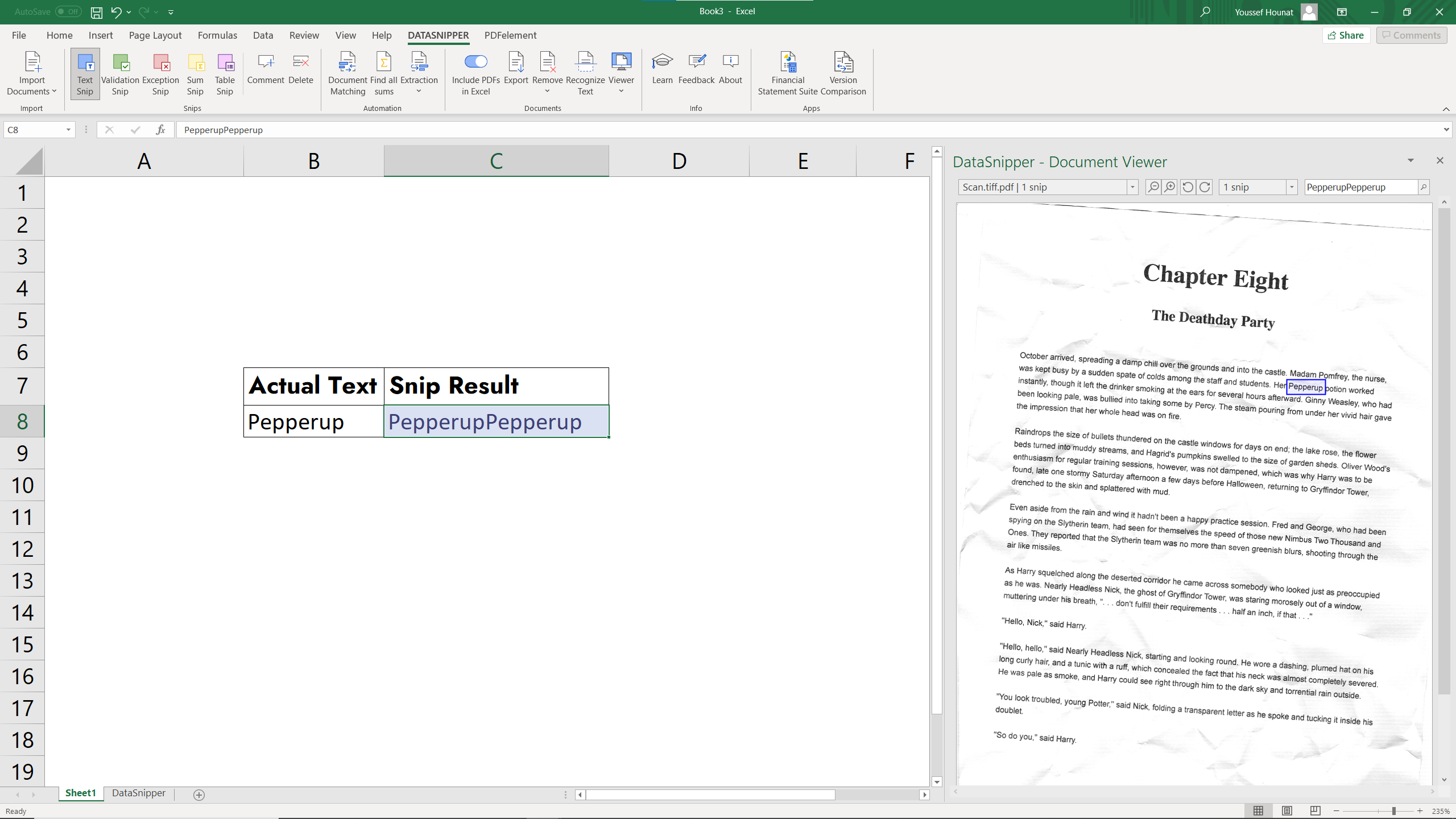

DataSnipper duplicate or unexpected text - how to resolve
This issue is caused by Optical Character Recognition from another application adding a new text layer on top of the existing text. This causes two sets of text to be embedded in the document even when only one is visible.
To resolve this, click the "Recognize Text" button in the DATASNIPPER ribbon.

Make sure "Recognize and overwrite previous text" is selected. This option is automatically selected from v3 onwards: